Dam101_unit6
Unit 6: Transformers, Introduction to Diffusion Models and Transfer Learning
Transformers
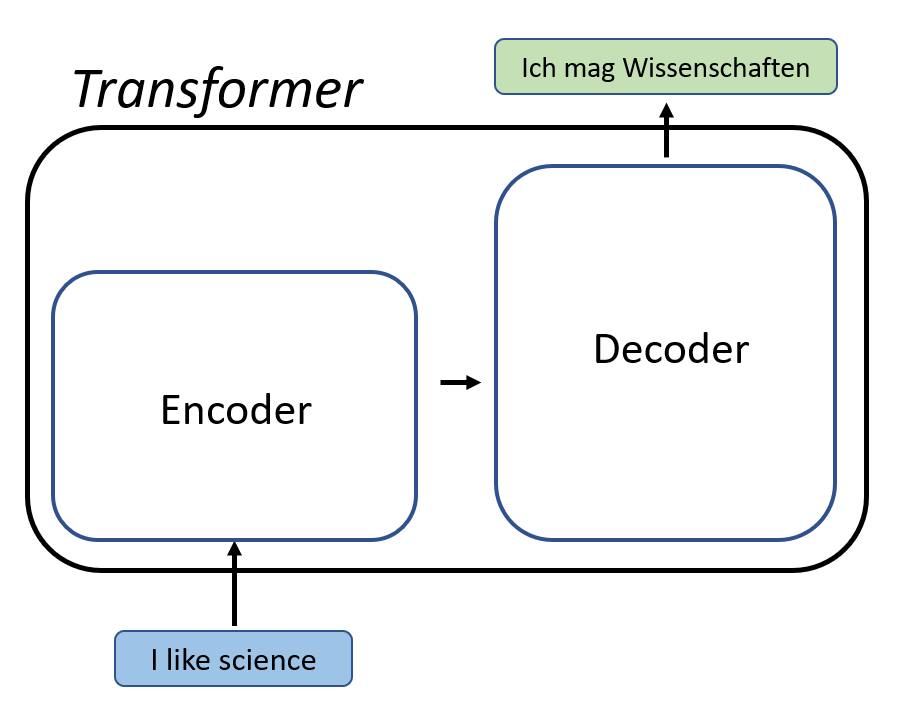
1. Transformer Network
Introduction: Transformers are a type of neural network architecture originally designed for natural language processing (NLP). They utilize a mechanism called attention to improve the processing of sequential data by focusing on relevant parts of the input.
Key Components:
Self-Attention: Allows each word/token in a sequence to attend to all other words/tokens, capturing relationships and dependencies.
Multi-Head Attention: Enhances self-attention by allowing the model to attend to different subspaces of representations simultaneously.
Architecture:
- Consists of an encoder-decoder structure.
- Encoder: Processes input sequences using multiple layers of self-attention and feed-forward neural networks.
- Decoder: Generates output sequences based on the encoder’s representations.
2. Implementing Transformers Architecture using DLL libraries
Deep Learning Libraries (DLL):
- TensorFlow, PyTorch, and other frameworks provide pre-implemented transformer layers and models.
- Users can customize these architectures for specific tasks such as machine translation, text generation, and sentiment analysis.
Steps:
- Utilize pre-trained models like BERT (Bidirectional Encoder Representations from Transformers) or GPT (Generative Pre-trained Transformer) for transfer learning.
3. Transformer Pre-processing
Pre-processing for transformers includes tokenization.
Tokenization:
- Converts text into numerical tokens suitable for input into the model.
- Includes handling special tokens (e.g.,
[CLS],[SEP]) and padding sequences for uniform input size.
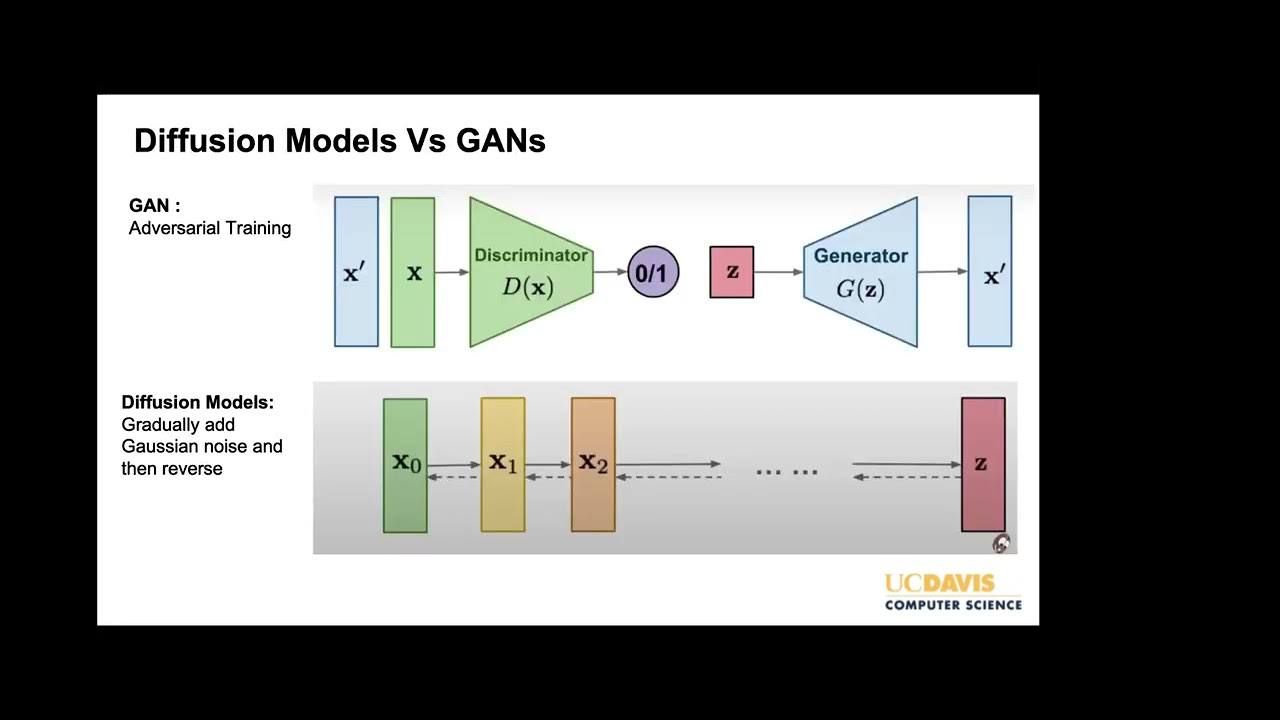
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a class of machine learning models where two neural networks, a generator and a discriminator, are trained adversarially.
- Purpose: The generator aims to produce realistic data instances that resemble the training data distribution, while the discriminator learns to distinguish between real data and generated data.
Components:
- Generator:
- Takes random noise as input and generates fake data samples.
- Trained to fool the discriminator into classifying generated data as real.
- Discriminator:
- Trained to differentiate between real data from the training set and fake data generated by the generator.
- Improves over time by learning to distinguish increasingly realistic generated samples.
Training Process:
- Adversarial Training:
- The generator and discriminator are trained iteratively.
- The generator aims to minimize the discriminator’s ability to correctly classify generated samples, while the discriminator aims to improve its classification accuracy.
Applications:
- Image Generation: Generating high-quality images from noise vectors.
- Data Augmentation: Creating synthetic data to augment training datasets.
Diffusion Models
Working of Diffusion Models
Diffusion models are generative models that simulate the process of data generation through iterative refinement.
- Mechanism: They model data evolution over time or steps, capturing dependencies between consecutive steps to generate realistic samples.
Key Concepts:
- Iterative Refinement: Samples are generated by iteratively refining a starting point to match the distribution of real data.
- Sequential Generation: Each step depends on the previous step, simulating a diffusion process.
Examples:
- Diffusion Variational Autoencoder (DVAE):
- Uses variational inference techniques to model the data diffusion process.
- Applications in generating high-quality images and videos.
Applications:
- Image and Video Synthesis: Generating realistic images and videos.
- Data Generation: Creating synthetic data for training machine learning models.
 —
—
Transfer Learning
Transfer learning involves leveraging knowledge gained from solving one problem and applying it to a different but related problem.
- Methods:
- Fine-tuning: Adapting pre-trained models on new datasets or tasks.
- Feature Extraction: Using pre-trained models as feature extractors for downstream tasks.
- Domain Adaptation: Adapting models trained on one domain to perform well on another domain.
Benefits:
- Reduction in Training Time: Saves computational resources and training time.
- Improved Performance: Especially useful in tasks with limited labeled data.
Applications:
- Natural Language Processing (NLP): Transfer learning models like BERT for various NLP tasks.
- Computer Vision: Using pre-trained CNNs for image classification and object detection.