Dam101_unit7
Unit 7: Reinforcement Learning
Reinforcement Learning
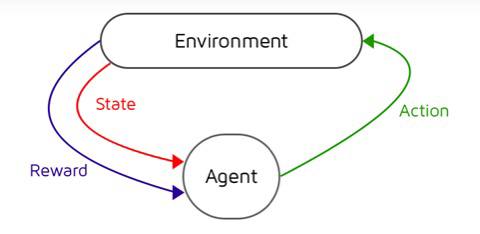
Reinforcement Learning (RL) is a branch of machine learning where an agent learns to make decisions in an environment to maximize cumulative rewards. It learns through interaction with the environment, observing states and rewards.
Markov Process, Markov Reward Processes (MRPs), Markov Decision Processes (MDPs)
Markov Process:
A stochastic process where future states depend only on the current state.
- State Transition: Transition probabilities define the likelihood of moving from one state to another.
Markov Reward Processes (MRPs):
- Extension: Includes rewards associated with each state.
- Expected Reward: Defines the expected cumulative reward starting from a given state.
Markov Decision Processes (MDPs):
- Incorporates Actions: Allows actions that influence state transitions and rewards.
- Components: States, actions, transition probabilities, rewards.
Policies in Reinforcement Learning
- Policy: Strategy or mapping from states to actions that the agent follows to maximize cumulative rewards.
Types:
- Deterministic Policy: Maps each state to a single action.
- Stochastic Policy: Probabilistic mapping from states to actions.
State-Action Value Function
- Q-Function (Q-value): Estimates the expected return starting from a state-action pair under a given policy.
Bellman Equation:
- Optimality: Q-value satisfies thee Bellman optimality equation for optimal policies.
Algorithm Refinement: e-Greedy Policy & Improved Neural Network Architecture
e-Greedy Policy:
- Exploration-Exploitation: Balances exploration (trying new actions) and exploitation (using known actions).
- Implementation: Chooses a random action with probability ε and the best action with probability (1-e).
Improved Neural Network Architecture:
- Deep Q-Networks (DQN): Uses deep neural networks to approximate Q-values.
- Advantages: Handles large state spaces and complex environments effectively.
- Training: Uses experience replay and target networks for stability.
This post is licensed under CC BY 4.0 by the author.